Fuentes de Datos Primarios: Datos Geográficos desde WFS
- H-Barrio

- 7 jun 2021
- 6 Min. de lectura
Los datos son el nuevo petróleo. Los datos son el nuevo oro. El mitril de Moria. Estas frases se utilizan para dar énfasis a los datos en la economía actual y el posible aumento de su valor en el futuro. No vamos a discutir estas comparaciones, vamos a asumir que los datos tienen un alto valor y que tanto como el oro o el petróleo, requieren de extracción y refinado para ser de alguna utilidad en la economía.
Hoy presentaremos un ejemplo de extracción y refinado de datos desde fuentes primarias. Estos datos no son, inicialmente, de carácter financiero. Recientemente hemos necesitado comprobar ciertos datos sobre el estado de la red ferroviaria en España y vamos a utilizar este grupo de datos como ejemplo especifico. El objetivo de la tarea es obtener las posiciones geográficas y los metadatos de la infraestructura ferroviaria para su análisis posterior. Los modelos de aprendizaje automático y de inteligencia artificial funcionan de maneras misteriosas; nunca sabes que tipo de datos vas a necesitar o como de profundos dichos datos están enterrados en la mina.
El cuaderno para esta entrada esta mas abajo, al final.

El conjunto de datos en cuestión lo publica la autoridad de infraestructura ferroviaria en España ADIF, a través de su "Web Feature Service". Los datos para información geográfica están generalmente codificados en "Geographic Markup Languaje" (GML). Estos datos y este formato son bastante venerables y usan un dialecto de XML en vez del mas "moderno" formato JSON. Estos datos no están, por lo tanto, en la superficie del planeta (una búsqueda en Google y ya); están enterrados bajo varias capas de formalidad y tenemos que excavar un pequeño pozo antes de obtener los datos.
Es posible que el lenguaje Python sea lento a la hora de procesar cálculos; también es un lenguaje en el que el desarrollo es muy rápido ya que existen bibliotecas para prácticamente todo. La biblioteca que vamos a necesitar esta vez para acceder a los WFS de ADIF es OWSlib, una parte de GEOPython.
Si no tenemos OWSlib instalado en nuestro sistema (y no lo esta por defecto en Google Colab) lo podemos instalar utilizando:
!pip install owslibTenemos que crear un objeto de conexión a WFS. Para ello, necesitamos la URL del servicio y la versión del protocolo de comunicación:
wfs_url = 'http://ideadif.adif.es/gservices/Tramificacion/wfs?request=GetCapabilities'
wfs = WebFeatureService(url=wfs_url, version='1.1.0')La URL es la especificada por el proveedor del servicio en su pagina. Siempre se puede acceder a ella utilizando un navegador para comprobar que el archivo GML esta aquí, un archivo en principio difícil de leer para un humano:
Utilizamos la versión de WFS 1.1.0 dada su estabilidad y mayor documentación. El dialecto XML usado en 1.1.0 parece mas sencillo de procesar que el de 2.0.0, aunque el proceso que aquí describimos será "poco atractivo" usando cualquiera de las versiones.
Comprobamos que el servicio al que estamos accediendo es, en efecto, el que necesitamos:
wfs.identification.title
#IDEADIF - GeoServer WFSPodemos comprobar las operaciones disponibles y el contenido de información:
[operation.name for operation in wfs.operations]
#['GetCapabilities', 'DescribeFeatureType', 'GetFeature', 'GetGmlObject']
list(wfs.contents)
#['Tramificacion:Dependencias',
'Tramificacion:PKTeoricos',
'Tramificacion:TramosServicio',
'Tramificacion:TramosFueraServicio']Los esquemas de datos para cada contenido se pueden verificar así:
print("Dependencias: " + str(list(wfs.get_schema('Tramificacion:Dependencias'))))
print("PKTeoricos: " + str(list(wfs.get_schema('Tramificacion:PKTeoricos'))))
print("TramosServicio: " + str(list(wfs.get_schema('Tramificacion:TramosServicio'))))
print("TramosFueraServicio: " + str(list(wfs.get_schema('Tramificacion:TramosFueraServicio'))))
'''
Dependencias: ['properties', 'required', 'geometry', 'geometry_column'] PKTeoricos: ['properties', 'required', 'geometry', 'geometry_column'] TramosServicio: ['properties', 'required', 'geometry', 'geometry_column'] TramosFueraServicio: ['properties', 'required', 'geometry', 'geometry_column']
'''El esquema para cada dato es similar, así que para obtener los elementos que necesitamos usamos:
theo_kmpoints = wfs.getfeature(typename='Tramificacion:PKTeoricos')Asignamos el resultado de una petición de los puntos kilométricos teóricos de la red ferroviaria. Este es un objeto _io.BytesIO que podemos leer y decodificar a UTF-8. El estándar Unicode que todo el mundo usa esta aquí.
byte_str = theo_kmpoints.read()
# Convert to a "unicode" object
kmpoints_text = byte_str.decode('UTF-8') El resultado es ahora un texto enorme mostrando una estructura similar a un XML. Podemos mirar la primera parte de los contenidos para inspeccionar que se trata de lo que estamos buscando.
kmpoints_text[0:2000] # First 2000 charactersPodemos guardar el texto a un archivo GML para utilizarlo mas adelante sin necesidad de repetir la petición al servidor:
out = open('theo_kmpoints.gml', 'wb')
out.write(bytes(kmpoints_text, 'UTF-8'))
out.close()Ahora hay que procesar el texto de tal manera que lo podamos leer como un diccionario de Python. Necesitamos un par mas de herramientas para simplificar este proceso, el procesador de XML para Python y dos clases para pasar nuestra información a listas y diccionarios, basado en esta receta:
from xml.etree import cElementTree as ElementTree
class XmlDictConfig(dict):
def __init__(self, parent_element):
if parent_element.items():
self.update(dict(parent_element.items()))
for element in parent_element:
if element:
if len(element) == 1 or element[0].tag != element[1].tag:
aDict = XmlDictConfig(element)
else:
aDict = {element[0].tag: XmlListConfig(element)}
if element.items():
aDict.update(dict(element.items()))
self.update({element.tag: aDict})
elif element.items():
self.update({element.tag: dict(element.items())})
else:
self.update({element.tag: element.text})
class XmlListConfig(list):
def __init__(self, aList):
for element in aList:
if element:
if len(element) == 1 or element[0].tag != element[1].tag:
self.append(XmlDictConfig(element))
elif element[0].tag == element[1].tag:
self.append(XmlListConfig(element))
elif element.text:
text = element.text.strip()
if text:
self.append(text)El diccionario XML (GML en concreto) es por lo tanto:
root = ElementTree.XML(kmpoints_text)
xmldict = XmlDictConfig(root)¿Qué es este diccionario? La estructura GML puede ser compleja ya que se trata de un estándar que admite múltiples capas lo que puede causar la repetición iterativa de claves de entrada o dataos anidados que requieran "cavar con demasiada codicia, y muy profundo" dependiendo del tipo de contenidos que queremos acceder. Aquí es donde empezamos a cavar. Primero, el nivel inicial de entradas es:
dict_keys = list(xmldict.keys())
dict_keys
'''
['numberOfFeatures',
'timeStamp',
'{http://www.w3.org/2001/XMLSchema-instance}schemaLocation', '{http://www.opengis.net/gml}featureMembers']
'''El numero de características, la anotación temporal, la localización y finalmente los miembros del paquete de datos. Hemos generado una lista con las claves de primer nivel ya que así podremos acceder a las entradas por posición de la clave durante nuestra prospección de datos:
print('Number: ' + xmldict[dict_keys[0]])
print('Time: ' + xmldict[dict_keys[1]])
print('Location: ' + xmldict[dict_keys[2]])
print('Members: ' + str(type(xmldict[dict_keys[3]])))
Podemos imprimir prácticamente todo, la entrada "members" no se puede imprimir ya que aquí es donde el diccionario de datos esta localizado; podemos imprimir una representación de la clase para evitar el error:
Number: 16824
Time: 2021-05-28T07:54:28.134Z
Location: http://ideadif.adif.es/tramificacion http://ideadif.adif.es:80/gservices/Tramificacion/wfs?service=WFS&version=1.1.0&request=DescribeFeatureType&typeName=Tramificacion%3APKTeoricos http://www.opengis.net/wfs http://ideadif.adif.es:80/gservices/schemas/wfs/1.1.0/wfs.xsd
Members: <class 'dict'>Los datos que buscamos están tras esta "veta", en el índice 3 del paquete de diccionarios y aun así dentro de una única clave intermedia:
km_points_data = list(xmldict[dict_keys[3]])
km_points_data
# ['{http://ideadif.adif.es/tramificacion}PKTeoricos']Los datos en crudo están por lo tanto dentro de la primera entrada del índice 3:
raw_data = xmldict[dict_keys[3]][km_points_data[0]]Para asegurarnos de que hemos encontrado el oro o el petróleo podemos mirar un elemento de datos al azar, ya que deberíamos tener 16824 entradas:
raw_data[80]
'''
{'{http://ideadif.adif.es/tramificacion}codtramo': '022000050', '{http://ideadif.adif.es/tramificacion}geom': {'{http://www.opengis.net/gml}MultiPoint': {'srsDimension': '2', 'srsName': 'urn:ogc:def:crs:EPSG::25830', '{http://www.opengis.net/gml}pointMember': {'{http://www.opengis.net/gml}Point': {'srsDimension': '2', '{http://www.opengis.net/gml}pos': '454114.02219999954 4476900.4242'}}}}, '{http://ideadif.adif.es/tramificacion}id_provinc': '28', '{http://ideadif.adif.es/tramificacion}pk': '15.3', '{http://www.opengis.net/gml}id': 'PKTeoricos.81'}
'''Esta es la "mena" de oro. Tenemos la codificación para una sección de la red ferroviaria, la descripción de los metadatos geográficos del punto en cuestión, las coordenadas el punto (en el estándar EPSG25830), un identificador de la provincia Española donde esta localizado el punto, el numero de punto kilométrico para la sección y el identificador, 81, ya que es la entrada en el índice 80. "Mena de datos" de la primera calidad, 16.824 entradas de datos que tenemos que refinar para simplificar su uso.
El refinado de estos datos para su posterior consumo por la industria, si usamos Python, implica transformar este conjunto de entradas a un dataframe de pandas. Tenemos que eliminar la información repetida de cada entrada: el metadato importante de geometría es siempre EPSG25830, y en este caso en particular es redundante. Como los datos ya se encuentran en forma de diccionario la forma mas simple, fea y poco pythonica es partir cada elemento de datos en pequeños diccionarios individuales para construir el susodicho dataframe con ellos. Podemos añadir cada elemento de datos dentro de una lista para hacer mas fácil su acceso:
data_elements = list(raw_data[0].keys())
data_elements
'''
['{http://www.opengis.net/gml}id', '{http://ideadif.adif.es/tramificacion}geom', '{http://ideadif.adif.es/tramificacion}pk', '{http://ideadif.adif.es/tramificacion}codtramo', '{http://ideadif.adif.es/tramificacion}id_provinc']
'''De estos elementos de datos, todos menos la información de geometría están disponibles directamente. Las coordenadas geométricas están mas profundamente enterradas en el esquema de datos. Como ejemplo, en la entrada de índice 0, las coordenadas que buscamos están aquí:
MultiPoint->pointMember->Point->pos
raw_data[0][data_elements[1]]['{http://www.opengis.net/gml}MultiPoint']['{http://www.opengis.net/gml}pointMember']['{http://www.opengis.net/gml}Point']['{http://www.opengis.net/gml}pos'] Para un texto de posición de 373512.03729999997 4495357.6887.
Nuestro bucle de extracción tiene esta pinta, con las horribles coordenadas extraídas de una larguísima cadena de llaves para los elementos de datos con índice 1:
total_points = len(raw_data)
total_points
coords = {}
km_points = {}
section = {}
province = {}
for elem in range(total_points):
index = raw_data[elem][data_elements[0]]
coords[index] = raw_data[elem][data_elements[1]]['{http://www.opengis.net/gml}MultiPoint']['{http://www.opengis.net/gml}pointMember']['{http://www.opengis.net/gml}Point']['{http://www.opengis.net/gml}pos']
km_points[index] = raw_data[elem][data_elements[2]]
section[index] = raw_data[elem][data_elements[3]]
province[index] = raw_data[elem][data_elements[4]]Cada punto geométrico esta ahora indexado con su correspondiente identificador "id" con las coordenadas, punto en sí, sección y la provincia como diccionarios individuales con el mismo índice. Ahora es sencillo crear un dataframe a través de diccionarios con claves consistentes:
import pandas as pd
pk_dataframe = pd.DataFrame([coords, km_points, section, province]).transpose()
pk_dataframe.columns = ['coords', 'km_point', 'section', 'province']
pk_dataframe.head()Para una forma final de datos refinados, en estado de puro dataframe, una pepita de datos:
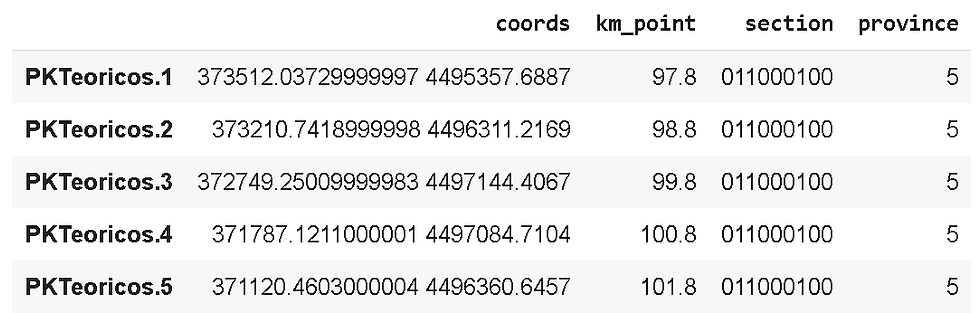
Y para hacerlo portable, lo mejor guardarlo como un archivo csv:
pk_dataframe.to_csv('PKTeoricos_ADIF.csv')En nuestra próxima entrada, veremos como sacarle partido a estos datos mediante su colocación y representación en la red ferroviaria usando Folium.
Si necesita ayuda en el desarrollo de modelos cuantitativos, su despliegue, verificación o validación no dude en contactar con nosotros. Estaremos encantados de ayudarle con sus programas de inteligencia artificial y su aplicación a la gestión de activos, automatizaciones o evaluaciones de riesgo.
Enlace al cuaderno en Google Colab: Notebook.
Comments